Font Recognition ML Model
Awarded as the winner team of more than 5,619 participants of the hackathon
Overview
This machine learning model is my team's work for participating in the Super AI Engineer Program Computer Vision Hackathon. The hackathon is hosted by the Association of Artificial Intelligence of Thailand (AIAT) with more than 5,619 participants. Other members include Mr. Nattapol Suwansawang, Mr.Nisit Smitsombun and Ms.Siripassaya Smitsombun.
Hackathon Overview


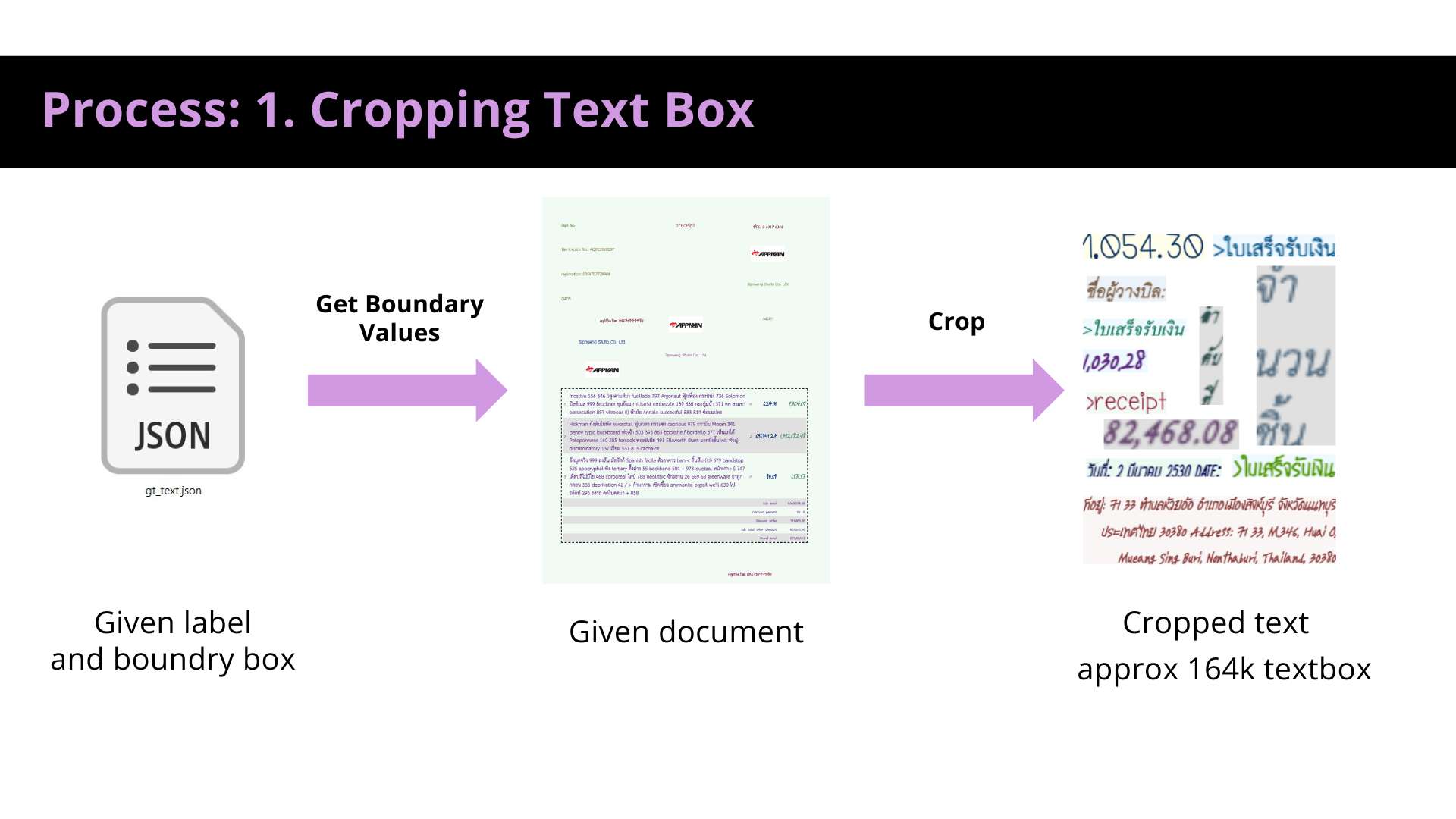
Preprocessing
Reasons for preprocessing data include but are not limited to:
- Cleaning and formatting the data in a way that the model can more easily learn from it.
- Reduce the complexity of the data and highlight important features that the AI model should pay particular attention to.



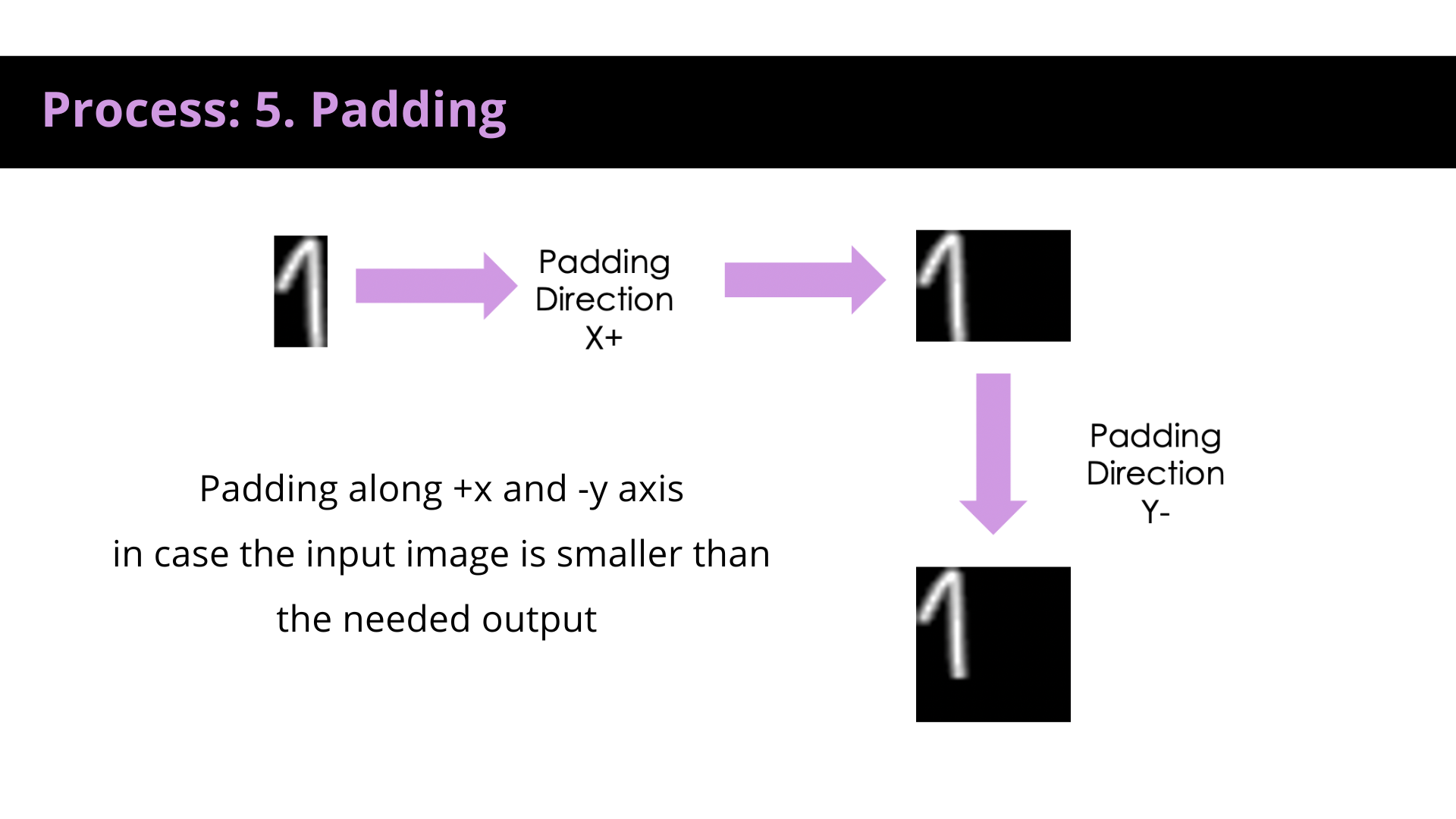
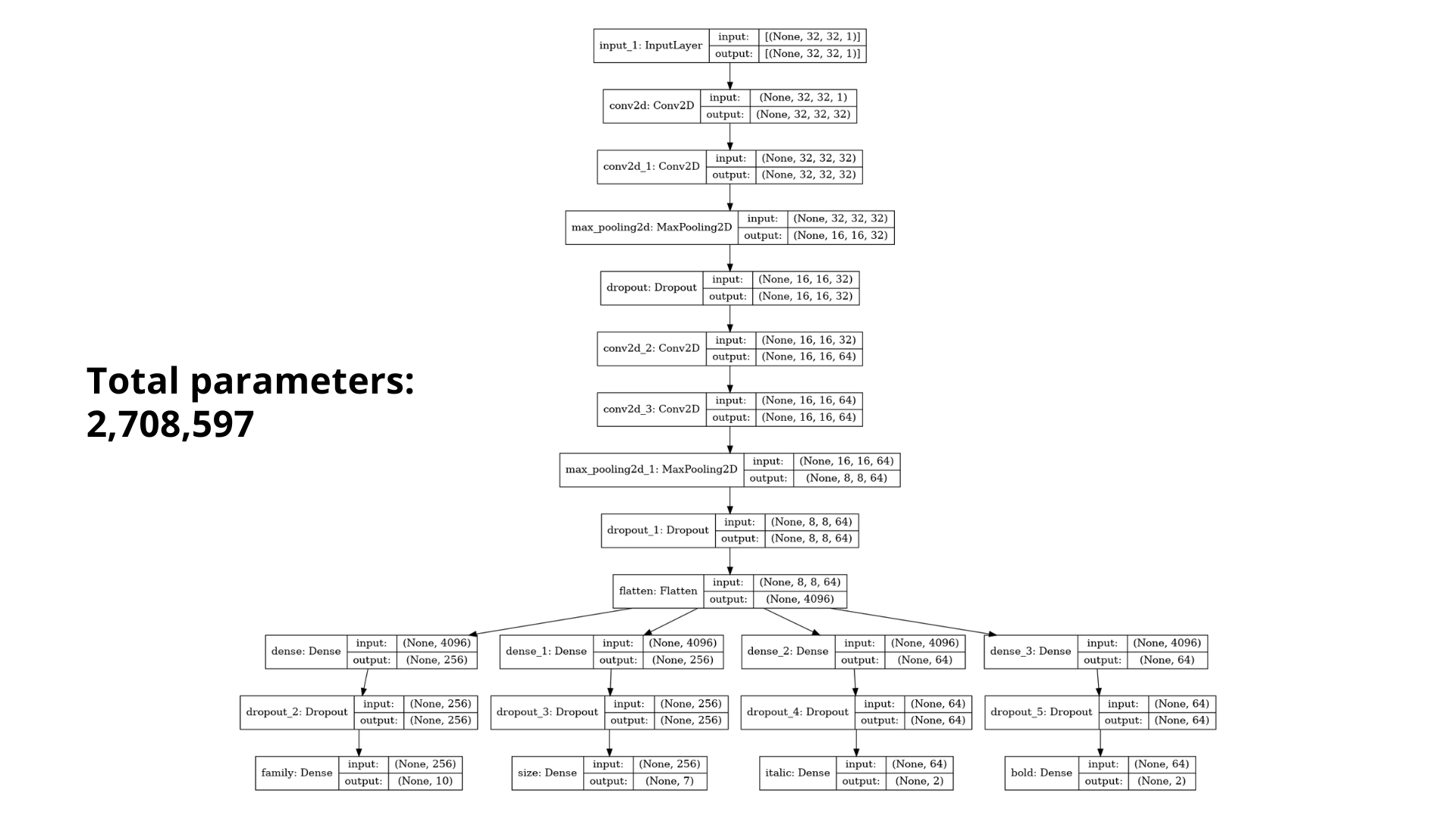
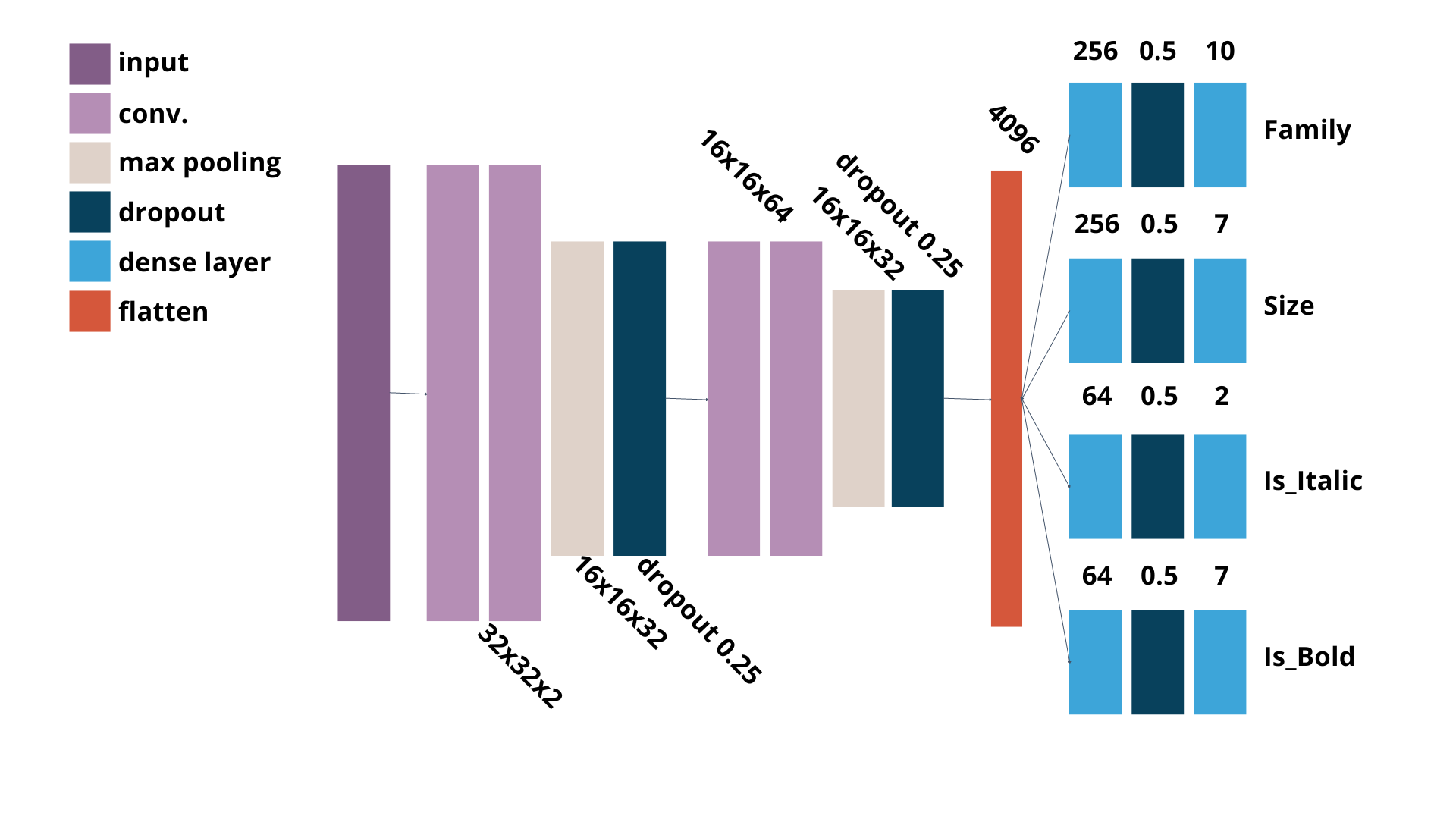
Main Model
We tried adopting transfer learning techniques along with implementing our own model by adopting idea we found from researching papers of the models which performed well in the MNIST problem. Furthermore, our team had the idea that fonts will impact the accuracy in determining other characteristics of the font. Therfore, we adopted categorial crossentropy loss so that our one model will be able to determine all four characteristics of an image.
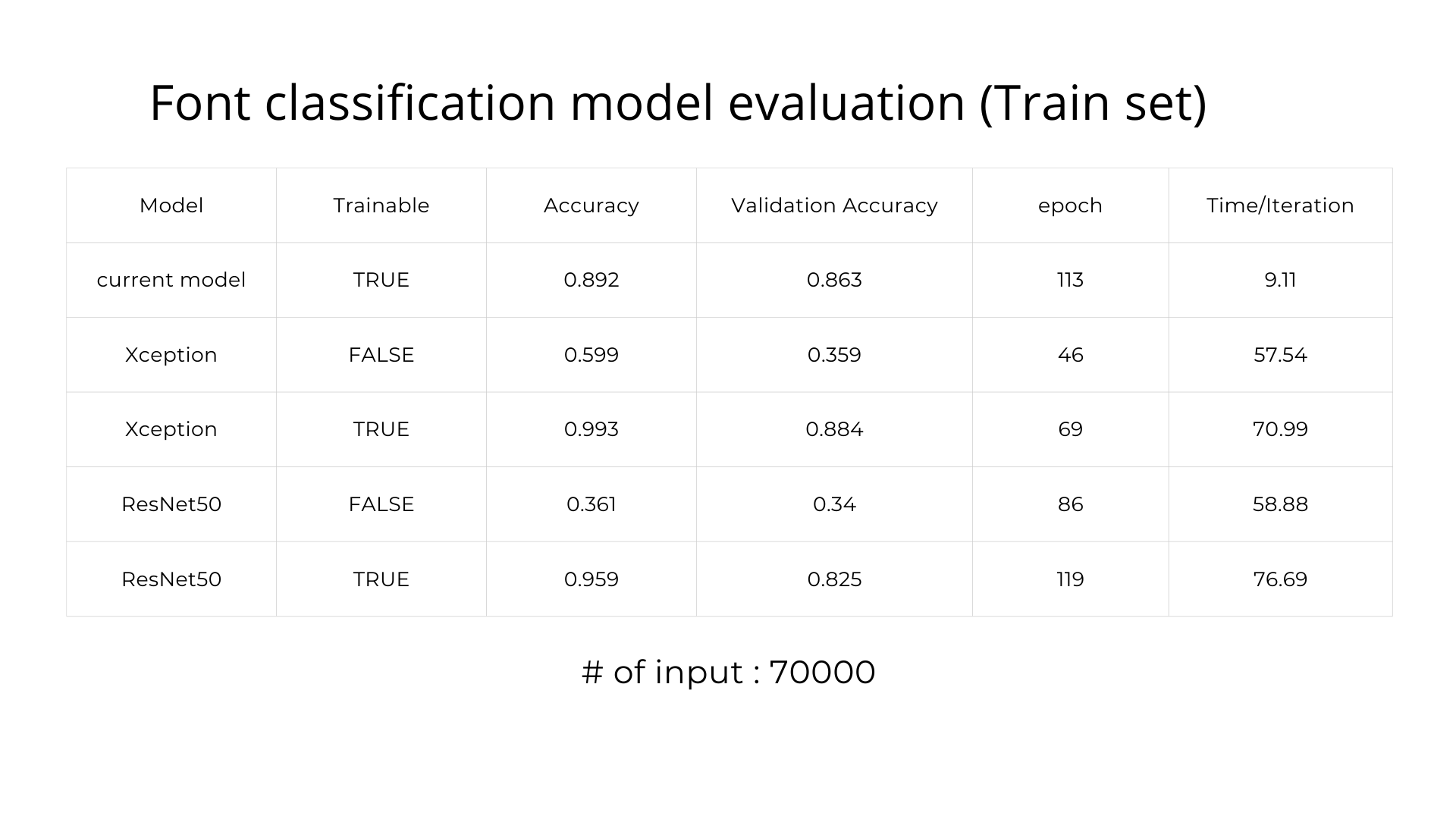
Evaluation
After comparing accuracy of our model with the transferred model of Xception and ResNet50, we decided to choose our current model to do the test set despite how its validation accuracy is behind transferred Xception model. The reason is that the time for training each epoch of our model is significantly lower than the transferred model but the validation accuracy is only 0.021 behind. Therefore, we were quite confident that our model will perform better if it was given more time to train. The reason we could not conduct more testing to prove our hypothesis was that there was a time limit for the hackathon.
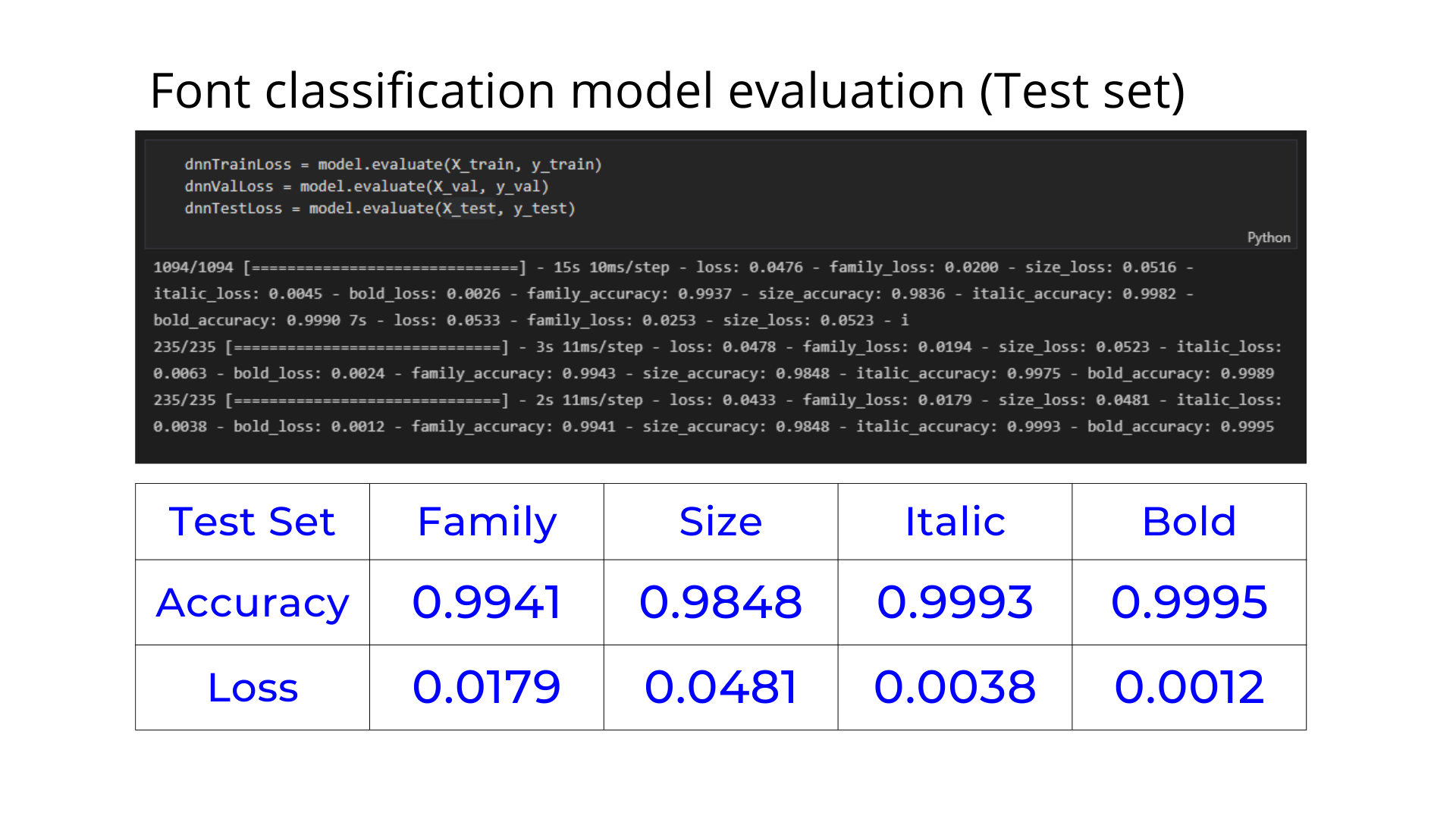
Further Improvement
Possible improvements include but are not limited to:
- Include additional step of removing background within the preprocessing process
- Include character recognization within our pipeline
- Conduct further research for idea to improve our main model structure